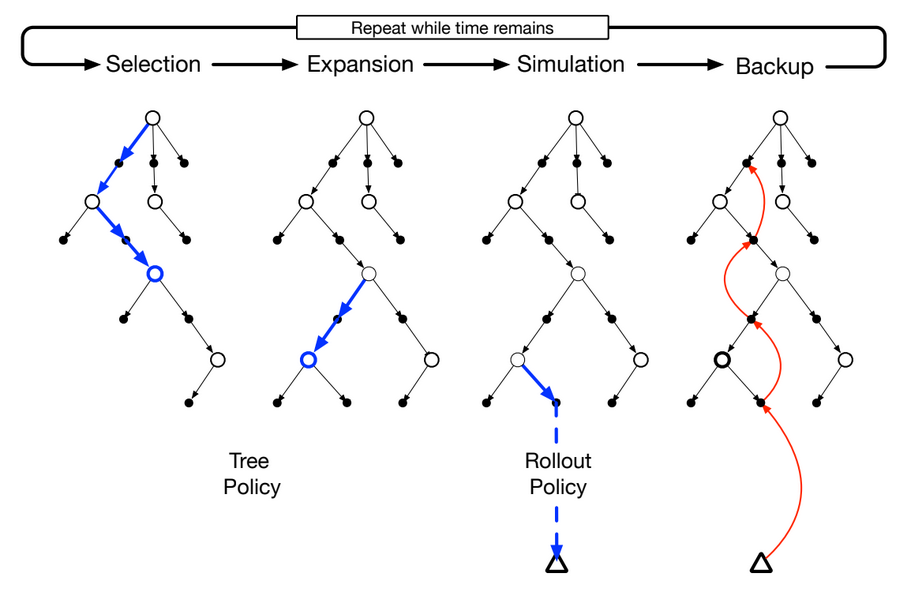
This is a review of the journal article “Motivational Profiling of League of Legends Players” by Brühlmann et al., 2020 [1].
Overview
The authors use an Organismic Integration Theory (OIT) based questionnaire called the User Motivation Inventory (UMI)[2], which is designed to measure player motivational regulations. After gathering 750 participants from the League of Legends subreddit (predominantly 17-25 year old males) they used the responses to this questionnaire to identify motivational profiles using Latent Profile Analysis (LPA)[3]. Responses to several other Self-Determination Theory (SDT), wellness, and experience based questionnaires, as well as in-game behaviour metrics, were also collected. These were aggregated and compared between the four different identified motivational profiles.

The authors find statistically significant differences in play experience based measures (how the player perceives the play experience and how it affects them) between the four identified profiles. They also find some statistically significant differences in play behaviour (what the players actually do when playing the game) between the four profiles.
Research Problem & Gap
Motivation, and SDT in particular, is a key research area within games research [5], but literature investigating how the motivational regulations of players affects the play experience and in-game behaviours is lacking.
There is also limited empirical work investigating how differences in motivational regulation affects psychological needs satisfaction. In other words if a player feels amotivated, extrinsically motivated, or intrinsically motivated, how does this impact the players’ psychological needs for competence, autonomy and relatedness when interacting with videogames? This paper aims to address these questions.
Contribution(s)
- The authors utilise a method to cluster responses to the User Motivation Inventory (UMI) questionnaire to identify four motivational regulation profiles of League of Legends players via a process called Latent Profile Analysis (LPA).
- These profiles are correlated with several other questionnaire responses designed to measure interest/enjoyment and pressure/tension, needs satisfaction, wellbeing, positive and negative associations, goal achievement and harmonious and obsessive passion. Doing so the authors show statistically significant differences in experience between players of different motivational profiles.
- The profiles are also used to compare aggregated in-game behaviour metrics between profiles, demonstrating some statistically significant differences in game playing behaviour (albeit less significant relative to the reported experience differences).
- This empirically validates that motivational regulations are related to the play experience and in-game behaviours of players of MOBA games.
Methods
Several SDT, wellbeing, and other psychological measures (questionnaires) are utilised where response are given using mostly answered using 5 or 7-point likert scales:
- User Motivation Inventory (UMI): a questionnaire based on the Organismic Integration Theory subtheory of SDT. This measures 6 factors including: amotivation, external regulation, introjected regulation, identified regulation, integrated regulation and intrinsic motivation.
- Player Experience Needs Satisfaction (PENS)[6]: a post-hoc SDT based questionnaire measuring needs satisfaction for competence, autonomy and relatedness.
- Vitality[7]: a measure intended to capture impacts on wellbeing (positive or negative).
- Intrinsic Motivation Inventory (IMI)[8]: the authors specifically adopt the interest-enjoyment and pressure-tension dimensions of the IMI. Authors hypothesise that these are experienced regularly by MOBA players.
- PANAS[9]: a measure intended to capture positive and negative affect. Authors hypothesise that these are experienced regularly by MOBA players.
- Achievement Goals[10]: measures a player’s achievement goals orientation (one of: mastery approach, mastery avoidance, performance approach and performance avoidance).
- Harmonious and Obessive Passion (HOP)[11]: a measure to identify autonomous and self-determined internalisation which does not interfere with other areas of life (harmonious), as well as identify non-self-determined internalisation due to external or internal pressure which may interfere with other areas of life (obsessive).

In-game behaviour metrics are also collected via the League of Legends API using participants’ provided summoner names (usernames). These aggregated metrics included time played, level, total matches, kills, assists, win rate, etc.
Latent Profile Analysis (LPA) is conducted on the responses to the UMI questions in order to identify four different motivational regulation profiles of the LoL players. Bayesian Information Criterion (BIC), Integrated Complete-data Likelihood (ICL) and Bootstrap Likelihood Ratio Test (BCLR), as well as authors’ own understanding of the profiles’ theoretical conformity were used to identify the appropriate number of profiles from the data.
The reason for conducting this Latent Profile Analysis was to produce profile labels which enable multi-dimensional analyses. For example, consider if one participant answered the intrinsic motivation (IMO) questions of the UMI very highly, but also answered the amotivation (AMO) questions highly. This participant may be very dissimilar to another participant who responds highly for IMO but low for AMO. The first participant may belong to the Amotivated profile, whereas the second would almost certainly belong to the Intrinsic profile. If we only considered high respondents for IMO as intrinsically motivated players, we would consider these two players the same. Hence clustering methods like LPA are necessary to perform more nuanced, multi-dimensional, and person-centric analyses. People are not one-dimensional, so our analyses should not be either!

The four profiles (and their distribution of values on each latent variable of the UMI) are shown above in Figure 3. Notice how Amotivated and External are similar, and Intrinsic and Autonomous are also similar. We will discuss these similarities later.
Results
Behavioural Game Metrics
The authors conducted a correlation analysis between the profiles and aggregated in-game metrics. These tell us how players who fit into each profile behave in the game on average.

Some interesting results pop up. First is that there aren’t many significant differences in the behaviour of the four different profiles. The main significant behavioural differences are: amotivated and autonomous players have higher mean winrate in unranked games, autonomous players have higher mean KDA in ranked games, and autonomous players have higher mean assists in unranked games. The remaining differences are not statistically significant.
Combined with the similarity of the profiles as per the UMI factors (Figure 2 above), the question arises as to why these profiles seem so similar. We’ll tackle this question shortly.
Player Experience
The authors also aggregated the results for responses to the other measures (questionnaire questions) by profile to see what the difference in player experience was between each profile. These tell us various things such as the extent to which the players experienced enjoyment, tension, feelings of positive/negative well being, psychological needs satisfaction and so on. The results are more interesting and are summarised below in Figure 5.

Describing this plot from left to right. All profiles reported high enjoyment, with the Intrinsic profile reporting highest levels of enjoyment. This is consistent with Organismic Integration Theory (see Figure 1), which posits that more integrated external regulations have more significant positive effects on wellbeing, engagement and enjoyment of an activity. Intrinsic motivation is believed to be the superior form of motivational regulation producing the highest levels of engagement, wellbeing and enjoyment.
Externally motivated players reported highest levels of tension. This may be due to their motivational regulation focussing on external outcomes, such as feeling pressure to perform well in the game to please their teammates, or to realise some internalised expectation of their own performance.
Intrinsically motivated players reported the highest levels of needs satisfaction for autonomy, which is also consistent with Organismic Integration Theory. There were not large differences in needs satisfaction for competence among the profiles, but Intrinsic and Autonomous reported slightly higher levels. For relatedness, the Amotivated profile reported significantly lower levels of needs satisfaction. This might indicate that Amotivated players do not feel a sense of connection or community with their fellow players whilst playing the game, and possibly avoid others whilst playing. This is consistent with their behavioural metrics: Amotivated players provide the lowest numbers of assists in both ranked and unranked, the highest number of kills in ranked mode, and the highest number of deaths in ranked and unranked. This suggests a maverick/solo playstyle for Amotivated players.
In terms of goal achievement, a standout result is that Intrinsically motivated players report the lowest levels of mastery and performance avoidance. This suggests that Intrinsically motivated players are not concerned with losing previously acquired knowledge or skills and are not concerned with performing worse than their peers or some normative standard. These goals are significantly higher for externally regulated players, from which we can infer they play due to an external or internalised pressure to perform highly and not lose their skill.
This result is supported by the significantly higher responses for obsessive passion for External regulated players. While not a high average response, it suggests their play habits might be more likely to interfere with other aspects of their lives in an unhealthy way. In contrast, intrinsically motivated players report the highest levels of harmonious passion, which is defined as “the autonomous and self-determined internalization of an activity into one’s identity (Vallerand et al., 2003), whereby the activity is aligned with different areas of a person’s life”.
The responses for Vitality support this finding further, where the Intrinsic profile reports the highest levels of Vitality and External reports somewhat lower levels of vitality. Vitality in this instance is defined as “positive feelings of aliveness and energy … hypothesized to reflect organismic well-being.”
However, the Amotivated profile reports the lowest levels of vitality, suggesting that disengagement and lack of understanding of why one plays LoL is somewhat detrimental to wellbeing.
Summary and Critical Reflection
In this paper the authors have demonstrated that different types of motivational regulation can relate to the player experience and in-game behaviour. The authors highlighted the distinction between motivational regulations (OIT) and psychological needs satisfaction (SDT), and how these two interact during gameplay. Their empirical analysis is extended to include measures of wellbeing, demonstrating that the different types of motivational regulation also impact players’ experience differently, with intrinsic motivation and more integrated forms of external regulation being the most desirable for player wellbeing.
The side-by-side comparisons of so many psychological measures in one study of video game players is extremely interesting and applicable to industry.
However, the sampling method may have biased the results towards players of a specific demographic (17-25 year old males) who are probably all highly engaged (interacting outside of the game on the subreddit is a strong indicator of overall engagement). This might explain why the four identified motivational profiles are very similar, in terms of the underlying UMI measure, additional measures, and in-game behaviours. Casting the net wider to find participants with varied levels of engagement might yield different results with more significant differences between the types of players.
In addition to the above, this use of gameplay behaviour metrics aggregated over the lifetime of the player assumes that a player’s motivational profile is static over the course of their interactions with a game. This is a big assumption. It assumes that motivational regulations are traits rather than states of the player. In other words: is it possible for a player to change from one motivational type to another over the lifetime of their engagement with a game, or even during the same play session? Organismic Integration Theory asserts that this is the case. If it is true, then comparing lifetime aggregated behavioural metrics between the profiles is less likely to reveal significant differences in behaviour.
References
[1] F. Brühlmann, P. Baumgartner, G. Wallner, S. Kriglstein, and E. D. Mekler, ‘Motivational Profiling of League of Legends Players’, Front. Psychol., vol. 11, 2020, Accessed: May 12, 2023. [Online]. Available: https://www.frontiersin.org/articles/10.3389/fpsyg.2020.01307
[2] F. Brühlmann, B. Vollenwyder, K. Opwis, and E. Mekler, ‘Measuring the “Why” of Interaction: Development and Validation of the User Motivation Inventory (UMI)’, Apr. 2018. doi: 10.1145/3173574.3173680.
[3] D. Spurk, A. Hirschi, M. Wang, D. Valero, and S. Kauffeld, ‘Latent profile analysis: A review and “how to” guide of its application within vocational behavior research’, J. Vocat. Behav., vol. 120, p. 103445, Aug. 2020, doi: 10.1016/j.jvb.2020.103445.
[4] Handbook of self-determination research. in Handbook of self-determination research. Rochester, NY, US: University of Rochester Press, 2002, pp. x, 470.
[5] A. Tyack and E. D. Mekler, ‘Self-Determination Theory in HCI Games Research: Current Uses and Open Questions’, in Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu HI USA: ACM, Apr. 2020, pp. 1–22. doi: 10.1145/3313831.3376723.
[6] R. M. Ryan, C. S. Rigby, and A. Przybylski, ‘The Motivational Pull of Video Games: A Self-Determination Theory Approach’, Motiv. Emot., vol. 30, no. 4, pp. 344–360, Dec. 2006, doi: 10.1007/s11031-006-9051-8.
[7] R. M. Ryan and C. Frederick, ‘On Energy, Personality, and Health: Subjective Vitality as a Dynamic Reflection of Well-Being’, J. Pers., vol. 65, no. 3, pp. 529–565, 1997, doi: 10.1111/j.1467-6494.1997.tb00326.x.
[8] E. McAuley, T. Duncan, and V. V. Tammen, ‘Psychometric Properties of the Intrinsic Motivation Inventory in a Competitive Sport Setting: A Confirmatory Factor Analysis’, Res. Q. Exerc. Sport, vol. 60, no. 1, pp. 48–58, Mar. 1989, doi: 10.1080/02701367.1989.10607413.
[9] D. Watson, L. A. Clark, and A. Tellegen, ‘Development and validation of brief measures of positive and negative affect: the PANAS scales’, J. Pers. Soc. Psychol., vol. 54, no. 6, pp. 1063–1070, Jun. 1988, doi: 10.1037//0022-3514.54.6.1063.
[10] A. J. Elliot and H. A. McGregor, ‘A 2 X 2 achievement goal framework’, J. Pers. Soc. Psychol., vol. 80, no. 3, pp. 501–519, Mar. 2001, doi: 10.1037/0022-3514.80.3.501.
[11] R. J. Vallerand et al., ‘Les passions de l’âme: On obsessive and harmonious passion.’, J. Pers. Soc. Psychol., vol. 85, no. 4, pp. 756–767, 2003, doi: 10.1037/0022-3514.85.4.756.