In the last post we discussed the problem of acting optimally in an episodic environment by estimating the value of a state. Monte Carlo Tree Search (MCTS) naturally fits the problem by incorporating intelligent exploration into decision-time multi-step planning. Give that post a read if you haven’t checked it out yet, but it isn’t necessary to understand today’s post. It might also be beneficial to get some intuition on UCB action selection.
Today we’re going to dig into ‘vanilla’ MCTS, the same algorithm used in state of the art game-playing agents like AlphaZero. When we’re done you’ll understand how and why this works so well for general game playing (especially in board games like Chess and Go).
Accompanying code snippets are included in the post to help explain the ideas. You can also follow along and run the code in this colab notebook. A python implementation of Connect4 is included in the notebook so you can play against the finished MCTS algorithm 😄 🔴🔵🔴🔴
The Four Steps in MCTS:
MCTS builds up estimates for the values of each possible state and action by planning ahead. In order to do this it must have a perfect model of the environment. In other words it must know exactly where it ends up after taking each action – without actually having to take that action. This is a downside to MCTS, since it can’t work without this model.
Anyway, assuming we have this perfect model we can simulate taking actions and choose the best ones based on the outcomes of simulated games. Doing so repeatedly we can build up a game tree of actions and states the algorithm has explored 🌳. Here are the four steps MCTS repeats to do this:
- Selection
- Expansion
- Rollouts/Simulation
- Backup of results
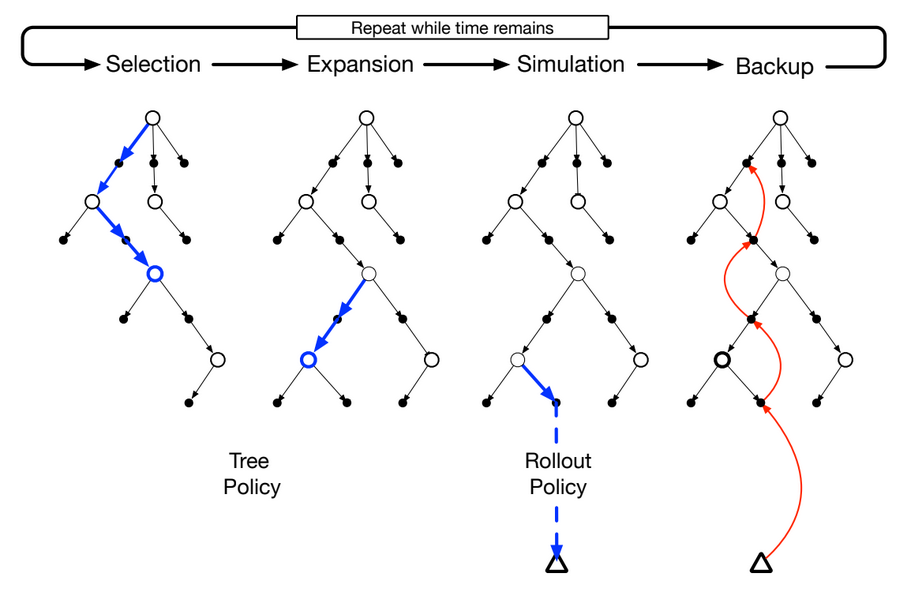
1. Selection:
MCTS starts by selecting the best node in the tree so far according to the UCB formula. This formula estimates the value (and uncertainty in that value) of each state in the tree. This form of MCTS is actually called “upper-confidence bound applied to trees” (UCT). Furthermore, UCT is just an extension of UCB action selection from multi-armed bandit problems, but applied to multi-step decision making instead. Here’s the UCB formula adapted to tree search (with explanation below):
\begin{aligned}
Score_i &= \bar{q}_i + U_i \\
&= \bar{q_i}+C \sqrt{\frac{2 \ln N}{n_i}}
\end{aligned}To demonstrate; think about this from the perspective of a parent node with several child nodes to consider. The action selection score of each child node is made up of the current estimate and uncertainty. The value estimate of the i-th child node is the current mean value of that node (\bar{q_i}). The uncertainty part has a constant C, that scales the uncertainty (bigger means more exploration, smaller means less exploration). We’ll leave this C=1. In the square root, N is the number of visits to the parent, and n_i are the number of times the child node i was chosen when passing through the parent N.
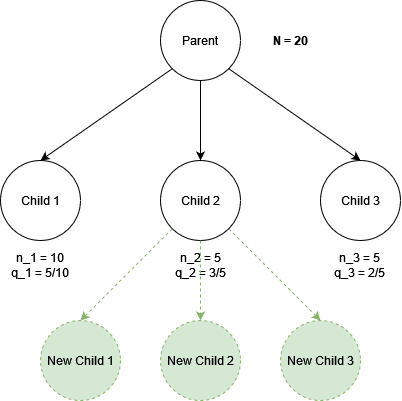
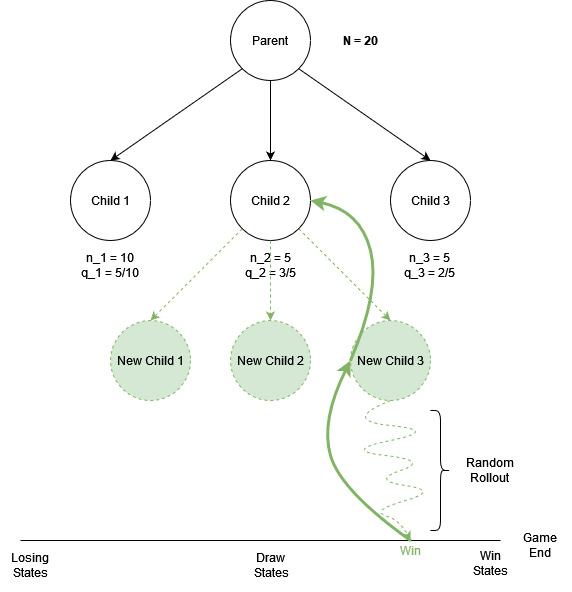
As an example, check the diagram below:

If we are in the parent node deciding which child node to explore, we apply the above UCB formula to each of the children and choose the one with the highest score. For instance evaluating child 1 and child 2:
\begin{aligned}
Score_1 &= \frac{5}{10} + \sqrt{\frac{{2\ln20}}{10}} = 1.274 \\
Score_2 &= \frac{3}{5} + \sqrt{\frac{{2\ln20}}{5}} = 1.694 \\
\end{aligned}According to this score the action selection will decide to further explore child 2. This is because we have explored Child 2 only 5 times, but exploring that child won 3 out of the 5 simulated games! This is a high win rate. We are also less certain about this result because the number of times explored is low (5). So the UCB action selection correctly pushes the algorithm to further explore this promising node 🧭.
Important side notes !!!
- When selecting from child nodes: if two children have an equal score, they must be selected from randomly. Any other tie-breaking method is not guaranteed to converge to an optimal policy.
- Additionally if a child node has not been explored at all (no visits) we automatically set it’s Q+U value to be +infinity (to guarantee exploring any unexplored children when visiting a parent node).
- Actually just about any bandit action selection algorithm could work in place of UCB. \epsilon-greedy for example.
Here’s the first part of the code in python, wrapped in a TurnBasedUCTNode class. We start in tree_policy():
class TurnBasedUCTNode():
def __init__(self,
env,
player_1_state,
player_2_state,
player_turn,
action=None,
reward=None,
parent=None,
id_in_parent=None):
self.env = env
self.player_1_state = player_1_state # 2d np array
self.player_2_state = player_2_state # 2d np array
self.player_turn = player_turn
self.action = action # which action was chosen previously Q(s,a)
self.parent = parent # parent node
# self.action != id_in_parent e.g. action may be 6, but id_in_parent may be 0
self.id_in_parent = id_in_parent # index of this child in parent's list of children
self.is_expanded = False
self.children = [] # list of child nodes
self.child_visit_count = None # need to expand before we know size of this list
self.child_q_sum = None # need to expand before we know size of this list
self.reward = reward
def child_q_estimates(self):
return self.child_q_sum/(self.child_visit_count+1)
def child_ucb1_estimates(self):
# handle case where we are at root with no parent
if self.parent is None:
my_visits = np.sum(self.child_visit_count)
else:
my_visits = self.number_visits
U = np.sqrt(2.0*np.log(my_visits)/(self.child_visit_count+1))
return U * EXPLORATION_CONSTANT
def select_best_child(self, max_value=1e6):
# Get Q + U for each child, return max, break ties randomly
if not self.is_expanded:
return self
q_u = self.child_q_estimates() + self.child_ucb1_estimates()
q_u[self.child_visit_count==0.0] = max_value
max_choices = np.flatnonzero(q_u == np.max(q_u))
if len(max_choices) == 1:
return max_choices[0]
random_choice = rando._randbelow(len(max_choices))
best_child_index = max_choices[random_choice]
return best_child_index
def tree_policy(self):
current = self
node_visits = 0
while current.is_expanded:
node_visits += 1
best_child_index = current.select_best_child()
current = current.children[best_child_index]
return current, node_visits # a not expanded leaf node2. Expansion:
This part is pretty easy to understand. Once selection reaches a node that has no children, we need to create those children. So we are expanding the tree. We do this by asking our simulated environment (perfect world model) which actions we can take given the state we are in. Then we take each of these actions in turn in our simulated environment and store the resulting states as new child nodes. Once this is done, we select one of these at random for the rollout/simulation stage.
The code for the expansion step is below, it is a method of the TurnBasedUCTNode class:
def expand(self):
if self.reward is not None:
return self
possible_actions = self.env.get_legal_actions(self.player_1_state,
self.player_2_state)
# perform action filtering in env.legal_actions to get legal actions
action_num = len(possible_actions)
if action_num == 0:
return self
next_player_turn = -1 if self.player_turn == 1 else 1 # flip player turn
self.child_visit_count = np.zeros(action_num, dtype=np.uint32)
self.child_q_sum = np.zeros(action_num, dtype=np.int32)
# loop thru legal actions and simulate stepping each one
i = 0
for action in possible_actions:
p1_state, p2_state, reward = self.env.step(action,
self.player_turn,
self.player_1_state.copy(),
self.player_2_state.copy())
child = TurnBasedUCTNode(self.env,
p1_state,
p2_state,
player_turn=next_player_turn,
action=action,
reward=reward,
parent=self,
id_in_parent=i)
self.children.append(child)
i+=1 # increment the index used for id_in_parent
self.is_expanded = True
# return a random child node for rollouts
random_child = self.children[rando._randbelow(len(self.children))]
return random_child3. Rollout / Simulation:
This part is pretty fun, and is at the heart of why MCTS works. It took me a while to get my head around this when I was first learning about MCTS. So I’ll spend some extra time on this section to map out the concepts and intuition.
You may have been wondering where the \bar{q_i} part came from in the UCB formula discussed earlier. It’s made up of two parts: the number of visits, and the sum of rewards. The number of visits makes sense, but where does the sum of rewards come from? It comes from the Monte Carlo rollouts 🧻.
In this stage the algorithm simulates a full game (all the way to the end) by randomly selecting actions for each player until the simulated game ends. Once that happens, the environment tells us if the game ended in a win/loss/draw, which is the reward.
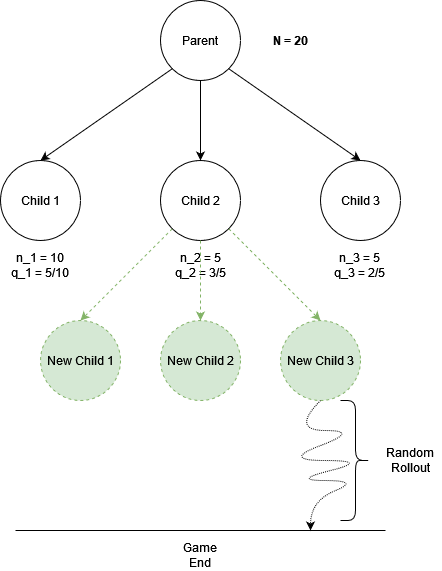
To clarify during rollouts we don’t need to create new nodes and copy state variables. Therefore the rollout stage is fast.
This still doesn’t really explain why rollouts work though. How does the result of a random game help us decide which actions to take?
A great way to think about this is as an extension of multi-armed bandit problems. In M.A.B.s we usually sample an action several times to build an estimate of its value. The same thinking applies here too. Hence, the more times we expand, reach a leaf node, and randomly rollout, the better the estimate of the value of each node/action.
To make this clearer: imagine if we sorted all of the possible end-game states from left to right, in order of lose, draw, win (see the diagram below). So a winning rollout will always land to the right, and a losing one to the left, and a draw is somewhere in the middle. In this visualisation we can imagine that good actions move us to the right, whereas bad actions move us to the left.
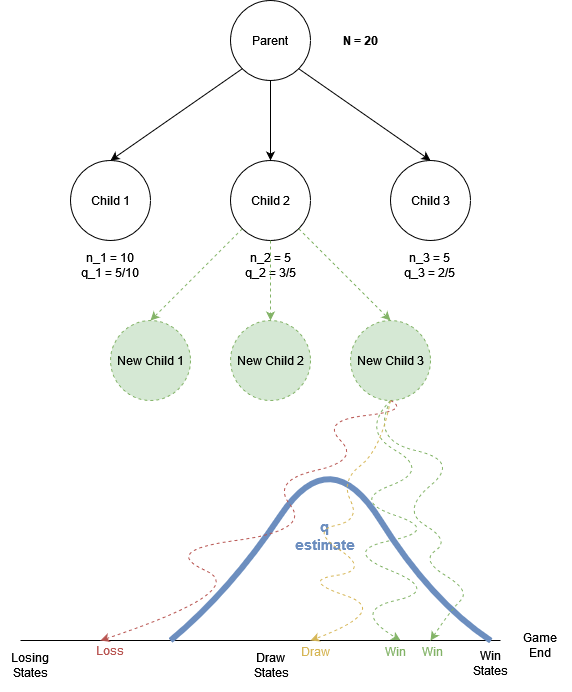
Consider that for any node we are building the probability density function of the rewards from the simulated games (-1, 0, +1). Therefore the q-estimate of a node is the mean of this p.d.f generated from rollouts that passed through this node. This allows us to determine if an action is good or bad! 😈
Code for the rollout method is shared below to neatly summarise:
def rollout(self):
max_t = (self.env.board_height*self.env.board_width)
# If this node is terminal state, backup reward immediately
if self.reward is not None:
self.backup(self.reward)
reward = None
temp_p1_state = self.player_1_state.copy()
temp_p2_state = self.player_2_state.copy()
rollout_turn = self.player_turn
while i < max_t:
# get legal actions from the environment
legal_actions = self.env.get_legal_actions(temp_p1_state, temp_p2_state)
# In this case, must be a draw.
if not legal_actions:
reward = 0
break
# choose random actions during rollouts
action = legal_actions[rando._randbelow(len(legal_actions))]
# don't need to copy states during rollout steps, just act on same state
temp_p1_state, temp_p2_state, reward = self.env.step(action,
rollout_turn,
temp_p2_state,
temp_p1_state)
# reward signals end of game
if reward is not None:
# reward is -1 if the player turn is not same as rollout turn
# in other words: this action led to eventual loss
if rollout_turn != self.player_turn:
reward = reward * -1
break
# flip player_turn on each loop
rollout_turn = -1 if rollout_turn == 1 else 1
self.backup(reward) # backup the reward4. Backup:
Once a rollout is complete we have to traverse the tree backwards and update the \bar{q_i} estimate of each node. This is done by incrementing its visit count and adding the reward from the rollout to its reward sum. Again, we need to backup so that each node is aware of the outcomes of games that ‘passed’ through it.
We first update the values in the leaf node, then move to the parent of that node and update those values, and so on. Until we reach the root node. At this point there is no parent, and we don’t need to update the values of the root node anyway.
Code for the backup method is provided below. Beware: we backup in a NegaMax fashion. Meaning we negate the value of the reward on each visit to subsequent parent nodes. Why? Because Connect4 is a two-player turn based game, so every second node is an opponent move. A win for us is a loss for the opponent. During the selection phase this allows MCTS to simulate the opponent picking the ‘best’ moves from their perspective during their turns! 🧠
def backup(self, reward):
current = self
if reward is None:
reward = 0.0
# in case we reached root
while current.parent is not None:
current.number_visits += 1
current.total_value += reward
current = current.parent
reward = reward * -1 # Ensure correct sign when backing up rewardsPlaying against MCTS in Connect 4:
Now it’s time to play against the AI we have created 🙂 You can do so by running the colab notebook, and interacting with the game at the very bottom of the notebook. 🔴🔵🔴🔴
- Open the link.
- At the top, click “Runtime”.
- Press “Run All”
- Scroll to the bottom and enter your moves in the text box (you are circles, see image below).

Adjusting the difficulty: The MCTS agent will take 5 seconds per turn. You can adjust the difficulty by giving the agent more or less time. Do this by passing adjusting the time_limit parameter in the uct_search function call.
for i in range(0, max_turns):
# p1: looks ahead using MCTS
root_node = TurnBasedUCTNode(env, p1_state, p2_state, player_turn=1)
action = uct_search(root_node, time_limit=7.0)
print(f"Chosen action: {action}")Summary:
We’ve seen how the MCTS algorithm works step by step. In summary: first the algorithm repeatedly selects nodes using the UCB action selection formula until it reaches a leaf node. It then expands a leaf node to create new child leaf nodes. Next, randomly selecting a new child leaf, the algorithm simulates a random game all the way to the end. The result or reward from that simulated game is then backed up the tree by revisiting each parent node. Furthermore, MCTS goes through this process repeatedly until some terminal condition is reached (usually a time limit). 📝
MCTS is one of the few general game playing algorithms out there. It doesn’t have any game-specific logic hard coded into it. Meaning we could drop the same algorithm into a different game like Chess and it would still work. All it needs is a simulator environment.
However, it also has its flaws. One of these is the need for the simulator environment – MCTS cannot plan ahead without one. This limits its use to situations where we have a simulator.
Future Work:
A relatively simple problem we could solve is that on every turn we build a brand new tree, decide on an action, and then throw the tree away. This means we’re rebuilding a lot of the same parts of the tree over and over again! With this in mind we could re-use the tree rather than starting from scratch each turn.
Another problem we could address is with the game-theoretic convergence. This means that in immediate sudden-death situations the algorithm must simulate many times in order to converge on the game theoretic win/loss value. We can address this problem by implementing a MCTS-Solver (a topic I’ll cover in future). 🛣️
Thanks for reading! 🙂